Klasifikácia datasetov scikit-learn
Zadanie č. 3d
Vašou úlohou je vytvoriť sofistikovanú neurónovú sieť, ktorá bude schopná klasifikovať dáta zo známeho datasetu dostupného v knižnici scikit-learn. Tento dataset obsahuje informácie o rôznych triedach, do ktorých má byť klasifikované a špecifikuje aj vlastnosti prvkov, ktoré budú slúžiť na klasifikáciu.
Dataset z knižnice scikit-learn obsahuje dôležité informácie, ktoré sa týkajú tried alebo kategórií, do ktorých je potrebné priradiť dáta. Tieto údaje o triedach sú kľúčovými pre cieľovú klasifikáciu a umožnia neurónovej sieti naučiť sa rozpoznať vzory a vzťahy medzi rôznymi triedami.
Okrem toho dataset obsahuje údaje o rôznych vlastnostiach alebo atribútoch, ktoré charakterizujú jednotlivé prvky datasetu. Tieto atribúty poskytujú podstatné informácie, ktoré sú vstupom pre neurónovú sieť a umožňujú jej učiť sa, ako tieto vlastnosti ovplyvňujú priradenie do rôznych tried.
Vaša úloha zahŕňa nasledujúce kroky:
- Zvoľte si a načítajte dataset zo scikit-learn a preskúmajte jeho štruktúru a obsah.
- Definujte architektúru neurónovej siete, ktorá bude vhodná pre klasifikáciu na základe zvoleného datasetu.
- Vhodne rozdeľte dataset na trénovaciu a testovaciu množinu.
- Trénujte zodpovedajúcu neurónovú sieť na trénovacej množine dát a sledujte jej schopnosť naučiť sa vzory a vzťahy medzi triedami a atribútmi.
- Vyhodnoťte výkonnosť neurónovej siete pomocou relevantných metrík (aspoň tri) a grafických vizualizácií.
- Vyskúšajte viacero typov neurónových sietí (tiež aspoň tri) a diskutujte o ich plusoch a mínusoch.
Ako výstup sa vyžaduje funkčná neurónová sieť, ktorej keď sa zadá akákoľvek vstupná vzorka, bude ju schopná zaradiť túto vzorku do správnej triedy.
Je dôležité, aby ste experimentovali s jednotlivými vrstvami siete a vyhodnotili, ako zmena parametrov ovplyvňuje klasifikáciu siete. (Nielen počty neurónov ale aj architektúra – voľba lineárnych či nelineárnych aktivačných funkcii, ich kombinácia a podobne.) Presnosť by mala určite presiahnuť 90%. Zadanie realizujte v ľubovoľnom frameworku (odporúčané Tensorflow alebo Pytorch).
Dokumentácia by mala vychádzať z krokov, ktoré boli spomenuté v zadaní. Mala by obsahovať dôvod voľby daného datasetu, bližší popis datasetu a jeho spracovanie. Taktiež by mala obsahovať odôvodnenie voľby zvoleného pomeru na testovacie a trenovacie dáta. Ďalej by mala obsahovať experimentovanie s architektúrou siete – k daným sieťam aj výsledky z metrík. Vyhodnotenie plusov a mínusov použitých architektúr sietí. Ak sa dá výsledok vizualizovať tak to spraviť. Ak sa nedá vizualizovať, treba vložiť do siete aspoň 5 rôznych vzoriek a tie klasifikovať.
Dostupné datasety v sklearn:
| Iris | California Housing |
| Diabetes | MNIST |
| Digits | Fashion-MNIST |
| Linnerud | make_classification |
| Wine | make_regression |
| Breast Cancer Wisconsin | make_blobs |
| Boston Housing | make_moons and make_circles |
| Olivetti Faces | Make_sparse_coded_signal |
Príklad vizualizácie: (trénovacia množina a testovacia s rozhodovacou hranicou)
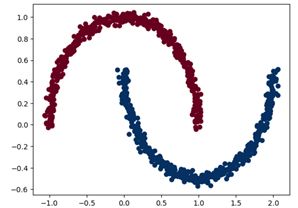 |
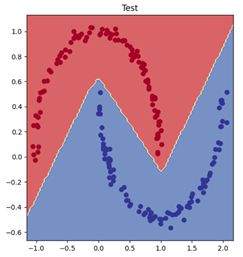 |